


Capstone believes increasing demand for artificial intelligence (AI) training data presents an opportunity for
web scrapers to expand their addressable market, making the sector attractive for private equity investors. Evolving
copyright laws and terms-of-service (TOS) claims are key, but manageable, risks. Scrapers using unauthenticated (no-
login) methods to collect publicly accessible data face lower exposure to litigation risk.
- The 2019 hiQ Labs v. LinkedIn precedent established that scraping publicly accessible data largely does not violate federal law. However, amid the surge in AI training data demand, content platforms are increasingly litigating against scraping activities, alleging copyright infringement and TOS violations.
- To mitigate this risk, AI developers are increasingly seeking to license data directly from major content platforms and employ third-party web scraping services. While third-party scrapers are also vulnerable to copyright and TOS litigation, we believe those using unauthenticated scraping methods are less exposed.
- This presents an opportunity for third-party web scrapers with legally defensible collection methods to expand their addressable market. Recent high-profile licensing deals— such as Alphabet Inc.-owned Google’s (GOOGL) $60 million annual contract with Reddit Inc. (RDDT) for training content—indicate strong multi-year pricing potential for third-party scrapers.
Background
As courts and regulators shift towards stricter copyright enforcement for AI model training, Capstone expects companies involved in data collection to see both significant opportunities and growing regulatory risks. While higher demand for AI training data creates tailwinds for registered data scrapers with access to large repositories of human knowledge, content holders are increasingly filing copyright infringement and breach of contract claims against companies that scrape unlicensed data for large language model (LLM) training. These legal developments create risks for scrapers, but we believe they are manageable—particularly given the otherwise stable regulatory environment around scraping publicly accessible data.
Recent licensing agreements between content holders and AI companies demonstrate the significant value AI companies place on training data. According to public reporting, content platform Reddit receives annual payments of $60 million from Google and $70 million from OpenAI—accounting for 10% of the company’s FY24 revenue—and is in talks with the two companies to renew and increase the deal values. OpenAI has struck many similar licensing deals with content platforms and news holders, including News Corp. (NWSA) for $250 million per year. These licensing agreements signal that AI developers are willing to pay significant premiums for access to data, especially when it mitigates copyright risk.
Web scrapers and data providers offer several specialized services that enable large-scale data collection, including residential proxy networks and IP rotation services that help avoid detection and blocking, CAPTCHA-solving tools that can bypass anti-bot measures, and “web unlocking” capabilities. As AI companies’ demand for training datasets grows, these scraping services have become increasingly valuable, with some data scrapers capitalizing on the opportunity by building AI training datasets directly. This represents an opportunity for third-party web scrapers, provided they monitor evolving copyright interpretations and TOS claims.
Litigation Developments
The regulatory environment around web scraping has been largely favorable for publicly accessible data since hiQ Labs v. LinkedIn, where the US Court of Appeals for the Ninth Circuit affirmed a lower court decision finding that collecting publicly available data does not violate the Computer Fraud and Abuse Act (CFAA), in a meaningful win for data scrapers. That precedent largely rules out CFAA liability, but it does not prohibit claims regarding breach of contract or terms-of-service (TOS) violations. In a later lower court ruling, the court found that hiQ violated LinkedIn’s User Agreement, which explicitly prohibited unlicensed scraping, providing website operators and content holders with a more effective legal theory in combating data scraping.
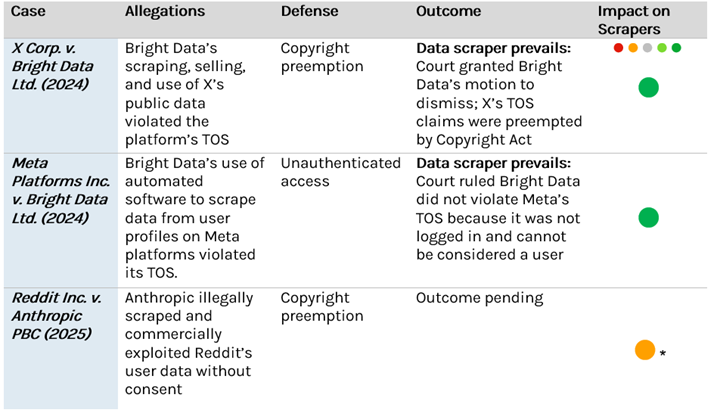
Recent key lawsuits, however, demonstrate that web scrapers have mostly successfully defended against state breach of contract claims when the targeted data is publicly accessible and not accessed via a login (see Exhibit 1) and when state claims conflict with federal privacy law.
- Authentication: In Meta Platforms Inc. v. Bright Data Ltd., Meta Platforms Inc. (META) sued the data collection company for scraping user data from its social media platforms. The court ruled in favor of Bright Data largely because it collected publicly visible data without logging into Meta’s platforms. Because the company scraped data without using credentials or authenticating, the court determined it was not a “user” bound by Meta’s User Agreement or TOS. By contrast, companies like LinkedIn have taken an aggressive stance against authenticated scrapers, banning browser extensions that scrape data while logged in on TOS enforcement grounds. Private equity investors should thus prioritize targets that use unauthenticated scraping methods, given stronger legal defensibility.
- Copyright Preemption: Courts have also dismissed state TOS claims that are preempted by federal copyright, i.e. Section 301 of the Copyright Act (see Exhibit 1). Conflict preemption, where federal copyright law overrides state laws and leads to their dismissal, has especially succeeded in cases brought by platforms with significant user-generated content. Courts have ruled that because users, rather than platforms, own the copyright to their posts, platforms cannot use state-law claims to restrict access to that content, as doing so would exceed their copyright authority and conflict with the Copyright Act.
Exhibit 1: Post-hiQ Labs v. LinkedIn data scraping cases and outcomes
Source: PACER, Capstone analysis
Note: In Reddit v. Anthropic, Anthropic moved the case to federal court, arguing “complete preemption.” We believe the case is likely to be returned to state court, as this type of preemption is more difficult to establish than “conflict preemption” (which was successfully established in X v. Bright Data).
*Outcome reflects Capstone’s prediction for the case
Since hiQ Labs v. LinkedIn, plaintiffs have also started pursuing data scraping allegations under the Digital Millennium Copyright Act (DMCA) anti-circumvention provisions, rather than unauthorized access claims. Google’s 2025 lawsuit against SerpApi exemplifies this strategy, arguing that the scraping company “unlawfully circumvents” Google’s technological barriers and bot-detection systems to scrape copyrighted content, even when publicly available. If successful, this legal theory could reshape data scraping law and create new legal exposure for businesses in the space.
What’s Next
Capstone is closely monitoring the Reddit v. Anthropic case in the US District Court for the Northern District of California, which is likely the next key litigation catalyst for data scrapers and related firms to watch. Reddit’s motion to remand the case back to the San Francisco County Superior Court remains pending. The parties will meet for a hearing on March 24, 2026. After the court rules on the jurisdictional questions, the case will proceed to discovery.
Read more from Capstone’s TMT Team:
The Growing Antitrust Risk for Pricing Software Firms
Too Big to Hide: Why Big Tech Platforms Will Face Continued Scrutiny
The Great Chip Chase: Implications of the Trump Administration’s Strategy to Win the AI Chip Race with China




